В предыдущем разделе мы агрегировали точечные данные по полигонам — определяли, сколько объектов попадает в каждую пространственную единицу. Однако зачастую одного подсчёта объектов недостаточно: важно также анализировать их атрибутивную информацию и рассчитывать по ней статистику.
В этом разделе мы рассмотрим, как агрегировать атрибутивные данные слоя с многоквартирными домами в Санкт-Петербурге по административным округам.
Выполним пространственное объединение: определим, к какому округу относится каждый дом.
Сгруппируем данные по округам и рассчитаем статистику по году постройки зданий (среднее, медиану, минимум и максимум).
Присоединим результаты к полигональному слою и визуализируем полученные показатели
0. Импорт библиотек и подготовка данных¶
0.1 Импорт библиотек¶
import pandas as pd
import geopandas as gpd
import matplotlib.pyplot as plt # модуль для построения графиков
import matplotlib as mpl # базовый модуль matplotlib 0.2 Подготовка данных¶
В этом разделе будут использованы файлы из нашего репозитория:
spb_admin.gpkg — полигональные данные о границах районов и округов Санкт-Петербурга.
Источник: материалы курса «Методы пространственного анализа», НИУ ВШЭ (Р. Гончаров)spb_mkd.csv — данные о многоквартирных домах (МКД) Санкт-Петербурга, 2020
Источник: Портал открытых данных Санкт-Петербурга
Прочитаем данные о границах округов в Санкт-Петербурге (spb_admin.gpkg)
okrug_gpkg = gpd.read_file("./data/spb_admin.gpkg", layer="okrug")
okrug_gpkg.explore(tiles="cartodbpositron")Прочитаем данные об МКД в Санкт-Петербурге и о границах районов
mkd_csv = pd.read_csv('./data/spb_mkd.csv')
#Посмотрим, как выглядят данные, чтобы понять, в каких полях записаны координаты
mkd_csv.head()Координаты записаны в поле coordinates, нам нужно разбить его на два поля: lat — широта и lon — долгота, а затем создать на их основе GeoDataFrame.
#Разбиваем поле с координатами на два
mkd_csv[['lat', 'lon']] = mkd_csv['coordinates'].str.split(',', expand=True).astype(float)
#На основе DataFrame создаем GeoDataFrame, определяя геометрию на основе координат
mkd_gdf = gpd.GeoDataFrame(mkd_csv, geometry=gpd.points_from_xy(mkd_csv['lon'], mkd_csv['lat']), crs=4326)Отобразим на карте первые 100 объектов из GeoDataFrame. Для всего набора данных этого лучше не делать, так как из-за большого объёма данных карта может не загрузиться
mkd_gdf[:100].explore(tiles="cartodbpositron")И посмотрим сводную информацию о получившемся GeoDataFrame
mkd_gdf.info()<class 'geopandas.geodataframe.GeoDataFrame'>
RangeIndex: 22771 entries, 0 to 22770
Data columns (total 52 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 addr_street 22771 non-null object
1 addr_number 22771 non-null object
2 addr_building 6736 non-null object
3 addr_letter 22674 non-null object
4 addr_district 22771 non-null object
5 comm_type 13498 non-null object
6 comm_num 13498 non-null object
7 comm_room_num 13498 non-null object
8 data_series 19298 non-null object
9 data_buildingdate 22769 non-null object
10 data_reconstructiondate 3616 non-null object
11 data_buildingarea 22768 non-null float64
12 data_livingarea 22771 non-null float64
13 data_nonolivingarea 13201 non-null float64
14 data_stairs 22668 non-null float64
15 data_storeys 22769 non-null float64
16 data_residents 22102 non-null float64
17 data_mansardarea 1240 non-null float64
18 eng_heatingcentral 22771 non-null float64
19 eng_heatingauto 22771 non-null float64
20 eng_heatingfire 22771 non-null float64
21 eng_hotwater 22771 non-null float64
22 eng_hotwatergas 22771 non-null float64
23 eng_hotwaterwood 22771 non-null float64
24 eng_electro 22771 non-null float64
25 eng_gascentral 22771 non-null float64
26 eng_gasnoncentral 22771 non-null float64
27 eng_refusechute 22756 non-null float64
28 flat_type 22343 non-null object
29 flat_num 22343 non-null object
30 flat_room_num 22343 non-null object
31 internal_num 8200 non-null float64
32 lift_exploitfromdate 8681 non-null object
33 lift_reconstructiondate 2865 non-null object
34 lift_repairdate 1357 non-null object
35 outclean_all 16461 non-null float64
36 param_crdate 21754 non-null object
37 param_ukname 22627 non-null object
38 param_failure 22771 non-null float64
39 repair_year 13662 non-null object
40 repair_job 13653 non-null object
41 rfc_shaftcount 6507 non-null float64
42 roof_metalarea 11485 non-null float64
43 seng_liftcount 10075 non-null float64
44 seng_pzu 17185 non-null float64
45 special_basementarea 18830 non-null float64
46 number 22771 non-null int64
47 address 22771 non-null object
48 coordinates 22771 non-null object
49 lat 22771 non-null float64
50 lon 22771 non-null float64
51 geometry 22771 non-null geometry
dtypes: float64(27), geometry(1), int64(1), object(23)
memory usage: 9.0+ MB
У нас, к сожалению, нет документации с описанием полей, однако мы можем примерно понять, какая информация в них содержится.
В рамках этого упражнения сосредоточимся на поле с годом постройки data_buildingdate. Для каждого из округов рассчитаем средний, медианный, самый ранний и самый поздний год постройки многоквартирных домов.
1. Пространственное объединение¶
Для начала нам нужно объединить слой с МКД со слоем с границами округов. Выполним пространственное объединение, чтобы определить, в каком округе находится каждый многоквартирный дом.
1.1. Проверка системы координат¶
Проверим, совпадают ли системы координат:
okrug_gpkg.crs == mkd_gdf.crsTrueВ нашем случае они совпадают, поэтому мы можем продолжить без перепроецирования.
1.2. Выполняем пространственное объединение¶
Для каждого многоквартирного дома (МКД) определяем округ, внутри которого он расположен. Для этого используем метод sjoin, в котором указываем тип пространственного предиката within, а также способ объединения данных (how="left"), чтобы сохранить все объекты из слоя с МКД.
mkd_in_okrug = gpd.sjoin(
mkd_gdf,
okrug_gpkg,
how="left",
predicate="within"
)В результате пространственного объединения к каждому дому добавляются атрибуты округа, где он расположен.
Посмотрим на результат — первые 5 строк нового набора данных.
mkd_in_okrug.head()2. Агрегирование атрибутивных данных¶
После выполнения пространственного объединения у нас есть информация о том, к какому округу относится каждый объект. Теперь можем перейти к анализу атрибутивных данных: сгруппируем объекты по округам и рассчитаем статистику по интересующему нас полю — году постройки зданий.
2.1. Проверка типа данных¶
Поскольку мы хотим рассчитывать количественную статистику, необходимо проверить тип данных поля data_buildingdate и убедиться, что оно имеет числовой тип, либо преобразовать их в числовой формат.
print(mkd_in_okrug[['data_buildingdate']].dtypes)data_buildingdate object
dtype: object
Видим, что поле data_buildingdate имеет тип object, то есть значения хранятся как строки. В таком формате мы не можем корректно рассчитывать числовую статистику, поэтому необходимо преобразовать это поле в числовой тип.
Преобразуем поле data_buildingdate в числовой формат с помощью функции pd.to_numeric. Параметр errors='coerce' позволяет заменить некорректные значения на NaN.
После этого проверим тип данных — теперь поле должно иметь числовой тип, что позволит корректно рассчитывать статистику.
#преобразование типа
mkd_in_okrug['data_buildingdate'] = pd.to_numeric(mkd_in_okrug['data_buildingdate'], errors='coerce')
#проверка типа после преобразования
print(mkd_in_okrug[['data_buildingdate']].dtypes)data_buildingdate float64
dtype: object
Отлично! Теперь мы точно можем рассчитывать количественную статистику на основе этого поля
2.2. Расчёт статистических показателей¶
Рассчитаем средний год постройки многоквартирных домов по округам. Для этого сгруппируем данные по округам и вычислим среднее значение, а затем присоединим результат к полигональному слою.
# Группируем данные по округам и считаем средний год постройки
build_year_mean = mkd_in_okrug.groupby('NAME')['data_buildingdate'].mean()
# Присоединяем результат к слою с округами
okrug_gpkg = okrug_gpkg.merge(
build_year_mean.rename('build_year_mean'),
on='NAME',
how='left'
)
# Визуализируем результат
okrug_gpkg.explore(column='build_year_mean', cmap='YlGnBu', tiles='CartoDB positron')Посмотрим на результат на карте
По аналогии посчитаем медианный, самый ранний и самый поздний год постройки.
# Рассчитываем медианный, минимальный и максимальный год постройки по округам
build_year_median = mkd_in_okrug.groupby('NAME')['data_buildingdate'].median()
build_year_min = mkd_in_okrug.groupby('NAME')['data_buildingdate'].min()
build_year_max = mkd_in_okrug.groupby('NAME')['data_buildingdate'].max()
# Объединяем все показатели в одну таблицу
stats = pd.DataFrame({
'build_year_median': build_year_median,
'build_year_min': build_year_min,
'build_year_max': build_year_max
}).reset_index()
# Присоединяем результаты к слою с округами по полю NAME
okrug_gpkg = okrug_gpkg.merge(stats, on='NAME', how='left')В данном примере группировка выполняется по полю NAME. В реальных задачах рекомендуется использовать уникальные идентификаторы, чтобы избежать возможных ошибок из-за совпадений или различий в названиях.
Убедимся, что новые поля успешно добавлены к данным.
#Посмотрим на первые несколько строк таблицы
okrug_gpkg[['build_year_mean', 'build_year_median', 'build_year_max', 'build_year_min']].head()Визуализируем все четыре показателя на отдельных картах, чтобы сравнить их между собой.
3. Картосхемы¶
Построим несколько карт и сравним показатели между собой. Чтобы сравнение было корректным, будем исрользовать единую цветовую шкалу.
3.1. Подготовка показателей для визуализации¶
Задаём список показателей, которые будем отображать. Для каждого показателя указываем:
название поля в данных
подпись для карты
metrics = [
('build_year_mean', 'Средний год постройки'),
('build_year_median', 'Медианный год постройки'),
('build_year_min', 'Самый ранний год постройки'),
('build_year_max', 'Самый поздний год постройки'),
]3.2. Определение общей цветовой шкалы¶
Находим минимальное и максимальное значения среди всех показателей.
Это нужно, чтобы:
все карты использовали один и тот же диапазон цветов
значения можно было корректно сравнивать между картами
# Общий диапазон значений для всех карт
vmin = okrug_gpkg[[m for m, _ in metrics]].min().min()
vmax = okrug_gpkg[[m for m, _ in metrics]].max().max()3.3. Создание карт¶
Создадим набор карт для всех показателей и отобразим их в одной строке. Для корректного сравнения будем использовать единую цветовую шкалу.
# Создаём область для отображения карт (1 строка, 4 столбца)
fig, axes = plt.subplots(1, 4, figsize=(20, 5), constrained_layout=True)
# Настраиваем цветовую шкалу
norm = mpl.colors.Normalize(vmin=vmin, vmax=vmax) # нормализация значений
cmap = mpl.cm.viridis # цветовая палитра
# Строим карты для каждого показателя
for ax, (metric, title) in zip(axes, metrics):
okrug_gpkg.plot(
column=metric, # какой показатель отображаем
ax=ax, # куда рисуем (конкретная "ячейка")
cmap=cmap, # цветовая палитра
norm=norm, # общий диапазон значений
linewidth=0.5,
edgecolor='gray'
)
ax.set_title(title, fontsize=12) # заголовок карты
ax.axis('off') # убираем оси
# Добавляем общую цветовую шкалу (legend)
sm = mpl.cm.ScalarMappable(cmap=cmap, norm=norm)
sm._A = [] # технический шаг для корректного отображения colorbar
cbar = fig.colorbar(
sm,
ax=axes.tolist(),
orientation='horizontal',
fraction=0.05,
pad=0.02
)
cbar.set_label('Год постройки', fontsize=12)
# Отображаем результат
plt.show()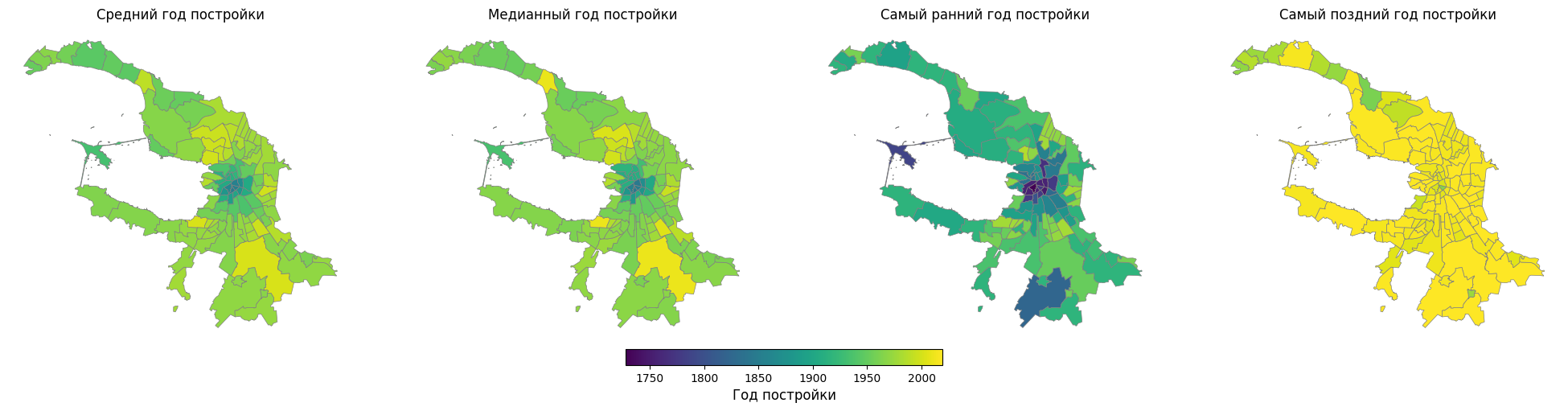
Итог¶
В этом разделе мы научились агрегировать атрибутивную информацию геоданных и анализировать её в разрезе пространственных единиц.
Мы повторили и узнали:
как с помощью пространственного объединения определить, к какой территории относится каждый объект;
как группировать данные по пространственным единицам и рассчитывать статистические показатели;
В рассмотренном примере мы анализировали год постройки многоквартирных домов. Однако аналогичный подход можно применять для любых атрибутивных данных.